실험 기간을 좀 더 늘리면 안 돼요?
실험을 한 번 진행했는데 통계적으로 유의하지 못한 결과를 얻었습니다. 기간을 조금 더 두고 실험을 하자니 시간이 오래 걸릴 것 같은데 기존 결과를 그대로 포함해서 실험 기간을 늘려서 보면 안 되나요?

회귀분석이란 무엇이며, 회귀분석 과정에서 사용하는 용어와 다양한 방법에 대해 알아보자.
!pip install --upgrade -q gspread
회귀분석은 변수 x(원인)가 변수 y(결과)에 주는 영향을 알기 위한 방법이다. 변수 x와 변수 y 사이에 있는 관계를 직선 또는 곡선의 식으로 나타낸 것을 회귀선이라고 한다.
import numpy as np
import matplotlib.pyplot as plt
# 데이터 만들기
marketing = np.random.randint(5, 40, 100)
sales = marketing * 2 + np.random.randint(-10, 10, 100)
# 산점도 그리기
plt.scatter(x = marketing, y = sales)
plt.xlabel('Marketing Spending')
plt.ylabel('Sales')
plt.axis([0, 40, 0, 100])
plt.show()
print('Correlation \n', np.corrcoef(marketing, sales))
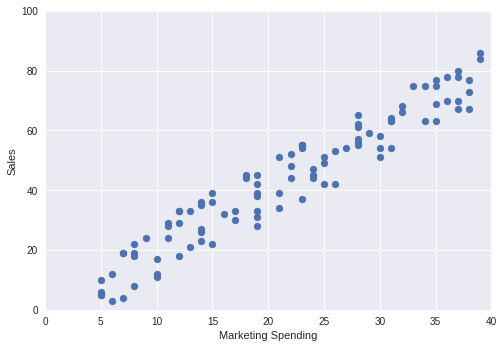
Correlation
[[1. 0.96068706]
[0.96068706 1. ]]
# sci-kit learn 라이브러리에서 linear_model 모듈 불러오기
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
lm = linear_model.LinearRegression()
model = lm.fit(marketing.reshape(-1, 1), sales)
sales_pred = model.predict(marketing.reshape(-1, 1))
print('Coefficients: \n', model.coef_) # 계수 확인하기
print('Mean squared error: %.2f'
% mean_squared_error(sales, sales_pred)) # RMSE 확인하기
print('Variance score: %.2f' % r2_score(sales, sales_pred)) # R-squared 확인하기
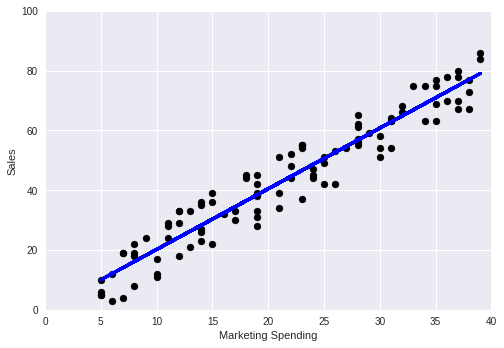
plt.scatter(marketing, sales, color = 'black')
plt.plot(marketing, sales_pred, color = 'blue', linewidth = 3)
plt.xlabel('Marketing Spending')
plt.ylabel('Sales')
plt.axis([0, 40, 0, 100])
plt.show()
Coefficients:
[2.02931856]
Mean squared error: 34.72
Variance score: 0.92
결정계수는 추정된 회귀선이 얼마나 관측 데이터에 들어맞을지(어느 정도의 적합성을 갖고 있을지)를 가늠하는 지표이다. 0에서 1 사이의 값을 취하며, 1에 가까울수록 전체 변동에서 추정된 회귀선으로 설명할 수 있는 변동이 높다는 말이다.
단순선형회귀에서의 결정계수는 관측값($y$)과 예측값($\hat{y}$)의 상관계수의 제곱과 같다.
\[R^2 = \frac{예측값으로 설명되는 변동}{전체 변동} = \frac{\sum(\hat{y_i} - \bar{y})^2}{\sum(y_i - \bar{y})^2}\]
# 결정계수
model.score(marketing.reshape(-1, 1), sales)
0.9229196312391211
추정된 회귀계수가 0과 같은 경우, 변수 x는 변수 y 의 원인이라고 할 수 없다. 이를 통계적으로 확인하기 위해 $H_0 : \beta_1 = 0\ vs\ H_1: \beta_1 \ne 0$ 으로 해서 가설검정을 한다.
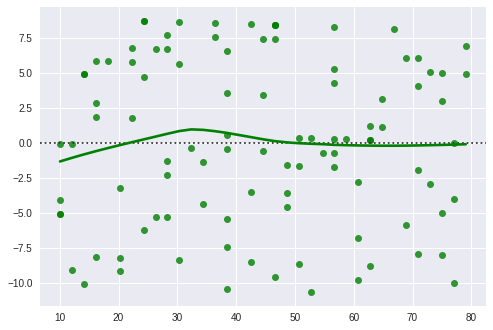
잔차($\hat{\epsilon}$) 와 예측값($\hat{y}$) 의 산포도(잔차 플롯)를 그리면 데이터의 문제(이상치가 포함되어 있음)나 모델의 문제(회귀식이 부적절)을 발견할 수 있다.
단순선형회귀분석에서 잔차 플롯은 아래의 항목들을 만족해야 한다.
import seaborn as sns
resid = sales - sales_pred
sns.residplot(sales_pred, resid, lowess = True, color = 'g')
설명변수가 여러 개 있을 경우는 다중회귀분석을 이용한다. 설명변수의 수가 다른 회귀식의 적합도를 비교할 경우에는 자유도 조정이 끝난 결정계수(Adjusted $R^2$)를 이용한다.
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
# 데이터 불러오기
dat = sm.datasets.get_rdataset('Guerry', 'HistData').data
# 데이터 확인하기
print(dat.describe())
# 회귀식 적합하기
model1 = smf.ols('Lottery ~ Literacy + np.log(Pop1831)', data = dat).fit()
model2 = smf.ols('Lottery ~ Literacy + np.log(Pop1831) + np.log(Crime_prop)', data = dat).fit()
# 결과 확인하기
print(model1.summary())
print(model2.summary())
dept Crime_pers Crime_prop Literacy Donations \
count 86.000000 86.000000 86.000000 86.000000 86.000000
mean 46.883721 19754.406977 7843.058140 39.255814 7075.546512
std 30.426157 7504.703073 3051.352839 17.364051 5834.595216
min 1.000000 2199.000000 1368.000000 12.000000 1246.000000
25% 24.250000 14156.250000 5933.000000 25.000000 3446.750000
50% 45.500000 18748.500000 7595.000000 38.000000 5020.000000
75% 66.750000 25937.500000 9182.250000 51.750000 9446.750000
max 200.000000 37014.000000 20235.000000 74.000000 37015.000000
Infants Suicides Wealth Commerce Clergy \
count 86.000000 86.000000 86.000000 86.000000 86.000000
mean 19049.906977 36522.604651 43.500000 42.802326 43.430233
std 8820.233546 31312.532649 24.969982 25.028370 24.999549
min 2660.000000 3460.000000 1.000000 1.000000 1.000000
25% 14299.750000 15463.000000 22.250000 21.250000 22.250000
50% 17141.500000 26743.500000 43.500000 42.500000 43.500000
75% 22682.250000 44057.500000 64.750000 63.750000 64.750000
max 62486.000000 163241.000000 86.000000 86.000000 86.000000
Crime_parents Infanticide Donation_clergy Lottery Desertion \
count 86.000000 86.000000 86.000000 86.000000 86.000000
mean 43.500000 43.511628 43.500000 43.500000 43.500000
std 24.969982 24.948297 24.969982 24.969982 24.969982
min 1.000000 1.000000 1.000000 1.000000 1.000000
25% 22.250000 22.250000 22.250000 22.250000 22.250000
50% 43.500000 43.500000 43.500000 43.500000 43.500000
75% 64.750000 64.750000 64.750000 64.750000 64.750000
max 86.000000 86.000000 86.000000 86.000000 86.000000
Instruction Prostitutes Distance Area Pop1831
count 86.000000 86.000000 86.000000 86.000000 86.000000
mean 43.127907 141.872093 207.953140 6146.988372 378.628721
std 24.799809 520.969318 109.320837 1398.246620 148.777230
min 1.000000 0.000000 0.000000 762.000000 129.100000
25% 23.250000 6.000000 121.383000 5400.750000 283.005000
50% 41.500000 33.000000 200.616000 6070.500000 346.165000
75% 64.750000 113.750000 289.670500 6816.500000 444.407500
max 86.000000 4744.000000 539.213000 10000.000000 989.940000
OLS Regression Results
==============================================================================
Dep. Variable: Lottery R-squared: 0.348
Model: OLS Adj. R-squared: 0.333
Method: Least Squares F-statistic: 22.20
Date: Sun, 09 Dec 2018 Prob (F-statistic): 1.90e-08
Time: 13:13:44 Log-Likelihood: -379.82
No. Observations: 86 AIC: 765.6
Df Residuals: 83 BIC: 773.0
Df Model: 2
Covariance Type: nonrobust
===================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------
Intercept 246.4341 35.233 6.995 0.000 176.358 316.510
Literacy -0.4889 0.128 -3.832 0.000 -0.743 -0.235
np.log(Pop1831) -31.3114 5.977 -5.239 0.000 -43.199 -19.424
==============================================================================
Omnibus: 3.713 Durbin-Watson: 2.019
Prob(Omnibus): 0.156 Jarque-Bera (JB): 3.394
Skew: -0.487 Prob(JB): 0.183
Kurtosis: 3.003 Cond. No. 702.
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
OLS Regression Results
==============================================================================
Dep. Variable: Lottery R-squared: 0.403
Model: OLS Adj. R-squared: 0.381
Method: Least Squares F-statistic: 18.44
Date: Sun, 09 Dec 2018 Prob (F-statistic): 3.11e-09
Time: 13:13:44 Log-Likelihood: -376.08
No. Observations: 86 AIC: 760.2
Df Residuals: 82 BIC: 770.0
Df Model: 3
Covariance Type: nonrobust
======================================================================================
coef std err t P>|t| [0.025 0.975]
--------------------------------------------------------------------------------------
Intercept 65.9147 74.285 0.887 0.377 -81.861 213.690
Literacy -0.3415 0.134 -2.544 0.013 -0.608 -0.074
np.log(Pop1831) -26.7902 5.990 -4.472 0.000 -38.706 -14.874
np.log(Crime_prop) 16.6622 6.099 2.732 0.008 4.529 28.796
==============================================================================
Omnibus: 2.539 Durbin-Watson: 2.052
Prob(Omnibus): 0.281 Jarque-Bera (JB): 2.431
Skew: -0.404 Prob(JB): 0.297
Kurtosis: 2.841 Cond. No. 1.55e+03
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 1.55e+03. This might indicate that there are
strong multicollinearity or other numerical problems.
from sklearn.datasets import load_boston
import pandas as pd
import statsmodels.api as sm
boston = load_boston()
boston_features = pd.DataFrame(boston.data, columns = boston.feature_names)
dummy_chas = pd.get_dummies(boston_features.CHAS)
boston_features = boston_features.join(dummy_chas)
boston_features = sm.add_constant(boston_features)
boston_features = boston_features.drop('CHAS', axis = 1)
boston_target = pd.DataFrame(boston.target, columns = ['MEDV'])
model = sm.OLS(boston_target, boston_features)
result = model.fit()
print(result.summary())
OLS Regression Results
==============================================================================
Dep. Variable: MEDV R-squared: 0.741
Model: OLS Adj. R-squared: 0.734
Method: Least Squares F-statistic: 108.1
Date: Mon, 10 Dec 2018 Prob (F-statistic): 6.95e-135
Time: 15:49:27 Log-Likelihood: -1498.8
No. Observations: 506 AIC: 3026.
Df Residuals: 492 BIC: 3085.
Df Model: 13
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 25.2236 3.407 7.403 0.000 18.529 31.918
CRIM -0.1072 0.033 -3.276 0.001 -0.171 -0.043
ZN 0.0464 0.014 3.380 0.001 0.019 0.073
INDUS 0.0209 0.061 0.339 0.735 -0.100 0.142
NOX -17.7958 3.821 -4.658 0.000 -25.302 -10.289
RM 3.8048 0.418 9.102 0.000 2.983 4.626
AGE 0.0008 0.013 0.057 0.955 -0.025 0.027
DIS -1.4758 0.199 -7.398 0.000 -1.868 -1.084
RAD 0.3057 0.066 4.608 0.000 0.175 0.436
TAX -0.0123 0.004 -3.278 0.001 -0.020 -0.005
PTRATIO -0.9535 0.131 -7.287 0.000 -1.211 -0.696
B 0.0094 0.003 3.500 0.001 0.004 0.015
LSTAT -0.5255 0.051 -10.366 0.000 -0.625 -0.426
0.0 11.2675 1.733 6.501 0.000 7.862 14.673
1.0 13.9561 1.781 7.836 0.000 10.457 17.455
==============================================================================
Omnibus: 178.029 Durbin-Watson: 1.078
Prob(Omnibus): 0.000 Jarque-Bera (JB): 782.015
Skew: 1.521 Prob(JB): 1.54e-170
Kurtosis: 8.276 Cond. No. 1.23e+18
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The smallest eigenvalue is 1.05e-28. This might indicate that there are
strong multicollinearity problems or that the design matrix is singular.
실험을 한 번 진행했는데 통계적으로 유의하지 못한 결과를 얻었습니다. 기간을 조금 더 두고 실험을 하자니 시간이 오래 걸릴 것 같은데 기존 결과를 그대로 포함해서 실험 기간을 늘려서 보면 안 되나요?
A/B 테스트란 무엇이고, 제가 왜 이게 통계학을 망치고 있다고 생각하는지 설명드리고자 합니다.
이 글은 AI가 데이터베이스에 직접 접근해 인간 전문가처럼 데이터를 분석하는 새로운 워크플로우를 소개합니다. 단순한 질의응답을 뛰어넘는 이러한 도약은 데이터 분석가의 역할이 근본적으로 재정의될 미래를 암시합니다.
이 글은 넷플릭스 (Netflix) 에서의 분석 엔지니어링 (Analytics Engineering) 관련 업무의 범위를 공유하기 위한 여러 편의 글 중 두 번째 글이며, 최근에 열렸던 분석 엔지니어링 컨퍼런스에서 발표된 내용이기도 합니다. 더 많은 내용이 궁금하신가요? 첫 번째 ...
듀오링고의 350% 성장의 뒷 이야기, 리더보드, 연속 학습, 알림, 그리고 혁신적인 그로스 모델 들어가기에 앞서
듀오링고의 350% 성장의 뒷 이야기, 리더보드, 연속 학습, 알림, 그리고 혁신적인 그로스 모델 들어가기에 앞서
듀오링고의 350% 성장의 뒷 이야기, 리더보드, 연속 학습, 알림, 그리고 혁신적인 그로스 모델
원문: Meaningful metrics: How data sharpened the focus of product teams
원문: Sequential Testing at Booking.com
가장 좋은 방법은 당연히 영어 밖에 사용하지 못하는 환경에 강제로 처해지는 것이겠지만 그것이 어려우니…
고민의 흔적을 보여주세요
을 찾습니다.
원문: Charts & Accessibility
모수, 큰 수의 법칙, 그리고 중심극한정리에 대하여
그리고 여러분들도 (아마도) 하지 않아야 하는 이유
회사 서비스의 추천 시스템을 개선하기 위해 팀 내에서 (아직까진 두 명이긴 하지만) 지난 두 달 동안 스터디를 진행했습니다. 얼마 전 두 번째 스터디가 끝났고 이에 대한 회고를 해보려고 합니다.
원문: Dark Side of Data: Privacy by Emre Rencberoglu
원문: RStudio Projects and Working Directories: A Beginner’s Guide by Martin Chan
원문: TidyTuesday GitHub Repository
원문: How programming languages got their names
원문: How to Make Meetings Less Terrible 팟캐스트: How to Make Meetings Less Terrible (Ep. 389)
생키 다이어그램 (Sankey Diagram) 은 흐름(Flow) 다이어그램의 한 종류로써 그 화살표의 너비로 흐름의 양을 비율적으로 보여준다.
2년 전 일본어로 책을 내긴 했지만 대부분의 독자들이 이 책을 읽을 수는 없을 것 같았다.
자기회귀 모형이란 무엇인가?
회귀분석을 실행하기 위해 필요한 가정과 조건들에 대해 알아보자.
통계적 검정과 회귀분석에서 자주 사용되는 정규성 가정과 정규성 검정에 대해 알아보자.
여러 통계 검정과 모형에서 사용되는 독립성 가정에 대해 알아보자.
시계열 모형 중 ARMA 모형에대해 알아보자.
시각화에서 주의할 점인 넓이를 표시하는 원칙에 대해 알아보자.
평균 양쪽의 z-값들 사이의 넓이를 구하는 방법에 대해 알아보자.
분산분석의 개념과 방법에 대해 알아보자.
분산분석(ANOVA; ANalysis Of VAriance) 와 회귀분석의 개념을 섞은 공분산분석(ANCOVA; ANalysis of COVAriance)에 대해 알아보자. 이 글을 이해하기 위해서는 아래의 글을 먼저 읽는 것이 좋다.
Akaike’s Information Criterion 의 정의와 이를 구하는 방법에 대해 알아보자.
수정된 R제곱과 그 용도에 대해서 알아보자.
통계 용어 중 정확도(Accuracy)와 정밀도(Precision) 에 대해서 알아보자.
절대 오차와 평균 절대 오차에 대해서 알아보자.
가설 검정이란 무엇이며, 가설 검정의 다양한 방법에 대해 알아보자.
회귀분석이란 무엇이며, 회귀분석 과정에서 사용하는 용어와 다양한 방법에 대해 알아보자.
이 글은 MathJax 를 GitHub Pages Jekyll blog 에 추가하는 방법을 다룬다. 이탤릭체로 된 부분은 본문에는 없고 제가 따라하면서 고치거나 추가한 부분이니 참고하세요.
모집단과 표본집단을 이용하는 경우 통계학에서 말하는 10% 조건이 무엇인지에 대해 알아보자.
여러분의 GitHub 블로그에 Jupyter notebook 을 바꿔서 올릴 수 있도록 도와줄 글입니다. 직접 바꾸는 방법은 1회성 글들을 위해서 추가했고, 변환 과정과 파일 이동, 그리고 여러분의 블로그에 올리는 것까지 한 번에 할 수 있는 자동화 bash 를 만드는 자세한 방법...
68 95 99.7의 법칙이란 무엇인가?
단위근 검정 방법 중 하나인 Augmented Dickey Fuller 검정에 대해 알아보자.
이 자료는 데이터 과학과 관련된 특정 주제에 대한 연재물이며, 다룰 주제는 다음과 같다. 회귀분석, 군집화, 신경망, 딥러닝, 의사결정나무, 앙상블, 상관관계, 파이썬, R, 텐서플로우, SVM, 데이터 축소, 피쳐 선택, 실험 계획법, 교차검증, 모델 피팅 등. 이 글을 계속 받...