실험 기간을 좀 더 늘리면 안 돼요?
실험을 한 번 진행했는데 통계적으로 유의하지 못한 결과를 얻었습니다. 기간을 조금 더 두고 실험을 하자니 시간이 오래 걸릴 것 같은데 기존 결과를 그대로 포함해서 실험 기간을 늘려서 보면 안 되나요?

듀오링고의 350% 성장의 뒷 이야기, 리더보드, 연속 학습, 알림, 그리고 혁신적인 그로스 모델
원문: Lenny’s Newsletter, How Duolingo reignited user growth
몇 달 전 제가 참석한 작은 행사에서 듀오링고의 전 CPO 인 Jorge Mazal 이 듀오링고의 재성장에 관한 뒷이야기를 해준 적이 있습니다. 저는 그 이야기에 되었습니다. 이전까지 단 한 번도 그정도의 성장을 들어본 적이 없었거든요. 이미 성숙한 제품에서 4.5배의 성장이 있었고, 그게 여러 개의 자그마한 제품 변화가 이를 이끌었다고 했고, 혁신적인 그로스 모델 (the Growth Model) 에 뿌리를 두고 있으며, 매우 자세한 행동에 대해서 설명해주었습니다. 그래서 저는 Jorge 에게 더 많은 사람들에게 (그리고 더 깊게) 그 이야기를 들려줄 생각이 있느냐고 물었고, 이에 동의해준 것에 매우 기쁩니다. 많은 제품들이 이미 듀오링고로부터 영감을 얻고 있으며, 이 이야기 덕분에 그런 경향이 더 크게 생길 것이라고 기대합니다. 시작하겠습니다!
더 많은 정보를 얻고 싶으시면 LinkedIn 과 Twitter 에서 Jorge 를 팔로우 하세요.

듀오링고는 항상 데이터 수집에 뛰어난 능력을 보여줬고, 특히나 A/B 테스트의 도움도 컸습니다. 하지만 이러한 데이터를 이용하여 인사이트를 만들어 내는데에는 큰 노력을 들이지 않았었습니다. Zynga 나 MyFitnessPal 내부에서 데이터를 사용하던 것과 비교해봤을 때 저는 듀오링고의 데이터를 이용하여 북극성 지표 (a North Star metric) 을 찾아서 필요했던 큰 변화를 이끌어낼 수 있을 것이라고 생각했습니다.
제가 Zynga 와 MyFitnessPal 에서 보냈던 시간들 덕분에 저는 사용자들을 관여 수준 (engagement level) 에 따라 나누는 것에 대한 영감을 얻을 수 있었습니다. Zynga 에서는 사용자를 나눠서, 다음과 같은 주간 리텐션 지표들에 기반하여 리텐션을 측정합니다.
그 다음 MyFitnessPal 에서 일하던 당시에 여기서는 Zynga 의 리텐션 작업을 차용하여 보다 확장한 것을 보았습니다. MyFitnessPal 에서는 성장을 측정하기 위해ㅐ CURR, NURR, 그리고 RURR 을 이용한 것뿐만 아니라, 미래의 시나리오를 모델링하기도 했습니다. 그리고 SURR 이라는 것도 도입했습니다.
저는 듀오링고에서도 이러한 지표들을 시작으로 하여 훨씬 더 정교한 모델을 만들 수 있을 것이라고 생각하였고, 이 모델을 이용하여 북극성 지표를 찾아낼 수 있겠다 싶었습니다. 획득팀 (the Acquisition Team) 의 데이터 과학자와 엔지니어링 매니저와 함께 저는 아래의 모델을 고안해냈습니다. 저희는 Zynga 와 MyFitnessPal 에서 사용한 것과 동일한 유지율 (retention rate) 을 이용하면서, 주간 지표의 관점을 살짝 틀어서 일간 지표로 만들었고, 몇 가지 지표들을 추가하였습니다.
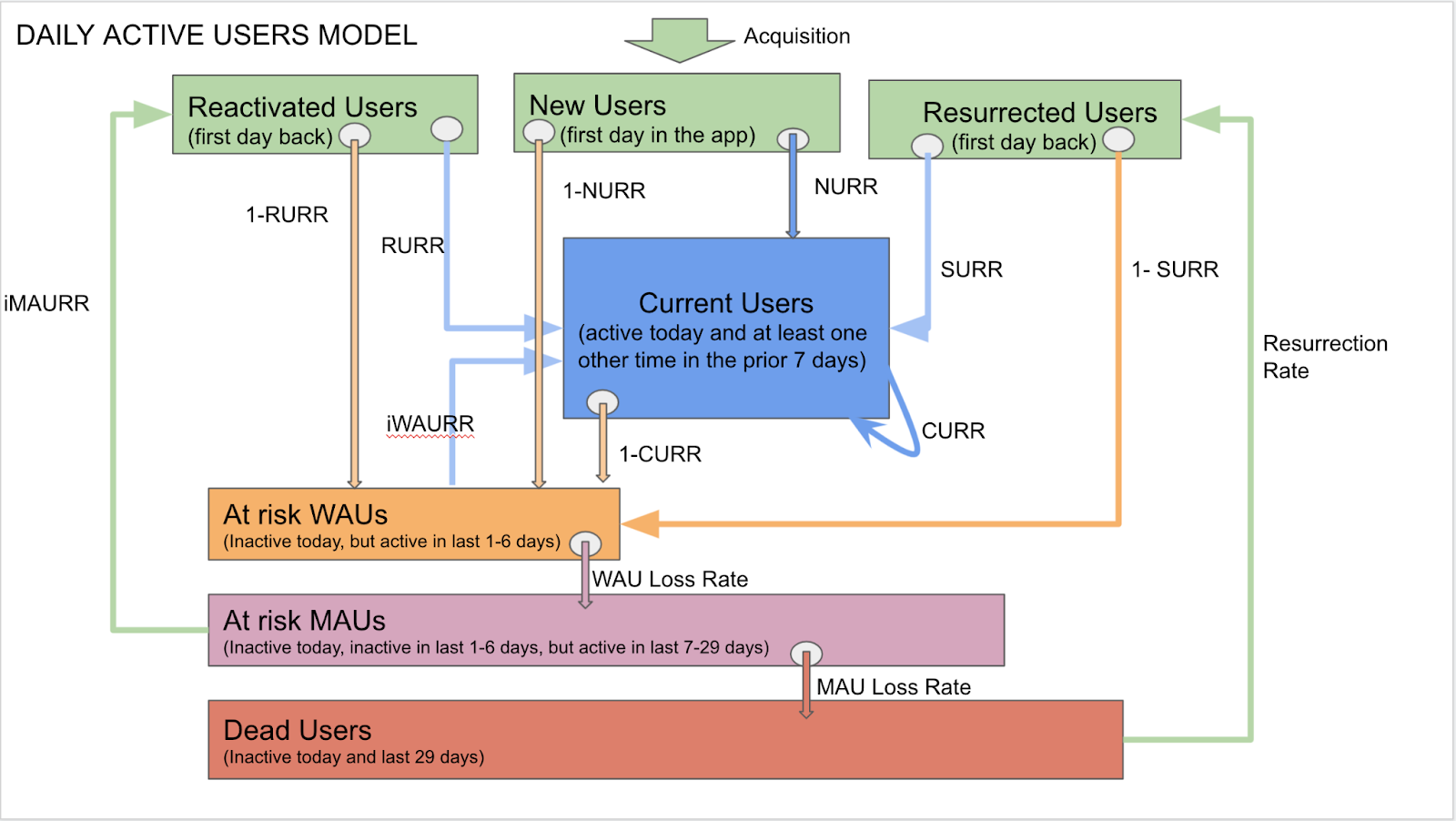
각 블록, 또는 바구니 (buckets) 는 각 서비스 이용 수준에 따른 사용자 세그먼트입니다. 그리고 서비스를 한 번이라도 이용한 적이 있는 사용자라면 특정 일자에 단 하나의 세그먼트에만 속하게 됩니다. 다시 말하자면, 이 모델에서의 바구니는 MECE (Mutually Exclusive, and Collectively Exhaustive, 상호 배타적이면서 전체를 포괄) 하게 듀오링고의 전체 사용자를 표현합니다. 화살표 는 각 바구니들 사이의 움직임을 측정합니다 (이는 CURR, NURR, RURR, 그리고 SURR 을 포함하며, 주간 유지율이 아니라 일간 유지율입니다). 바구니와 화살표를 합쳐서 이 모델은 폐쇄회로 시스템 (closed-circuit system) 을 구성하고 있으며, 신규 사용자만이 이를 벗어나있습니다.
편리하게도 위쪽에 위치한 4개의 바구니를 합치면 일간 활성 사용자 (DAU) 가 되고, 정의는 아래와 같습니다.
그리고 나머지 3개의 바구니는 당일에 앱을 이용하지 않은 사용자들을 나타내며, 각각의 비활성 정도에는 차이가 있습니다.
이 세그먼트를 이용하여 DAU, WAU, MAU 를 쉽게 계산할 수 있었던 덕분에 장기간에 걸친 모델링을 수월하게 할 수 있었습니다. 그리고 이 모델의 핵심 기능이기도 합니다. 게다가, 화살표로 표현된 유지율 지표들을 조작하면서, 저희는 이러한 지표를 움직이는 것에 대한 복리 효과와 누적 효과를 모델링할 수 있었으며, 이는 이러한 유지율 지표들이 DAU 를 성장시키기 위해 제품팀이 당길 수 있는 레버였다는 말입니다.
모델을 만들고 나서, 저희는 지난 몇 년 동안 사용자 세그먼트와 유지율들이 하루하루 어떻게 변화했는지를 살펴보기 위해 스냅샷을 찍기 시작했습니다. 이 데이터를 이용하여 저희는 앞을 보는 모델을 만들 수 있었고, 어떤 레버가 DAU 성장에 가장 큰 효과를 가지고 있는지를 예측하기 위한 민감도 분석을 수행할 수 있었습니다. 저희는 각 유지율에 대해 다른 유지율은 그대로 둔 채 하나의 비율을 매 분기 2% 올렸을 때 DAU 가 어떻게 변하는지를 시뮬레이션 했습니다.
아래는 첫 시뮬레이션의 결과입니다. 각 레버에 대해 2% 의 작은 변화가 MAU 와 DAU 에 끼친 영향을 볼 수 있습니다.
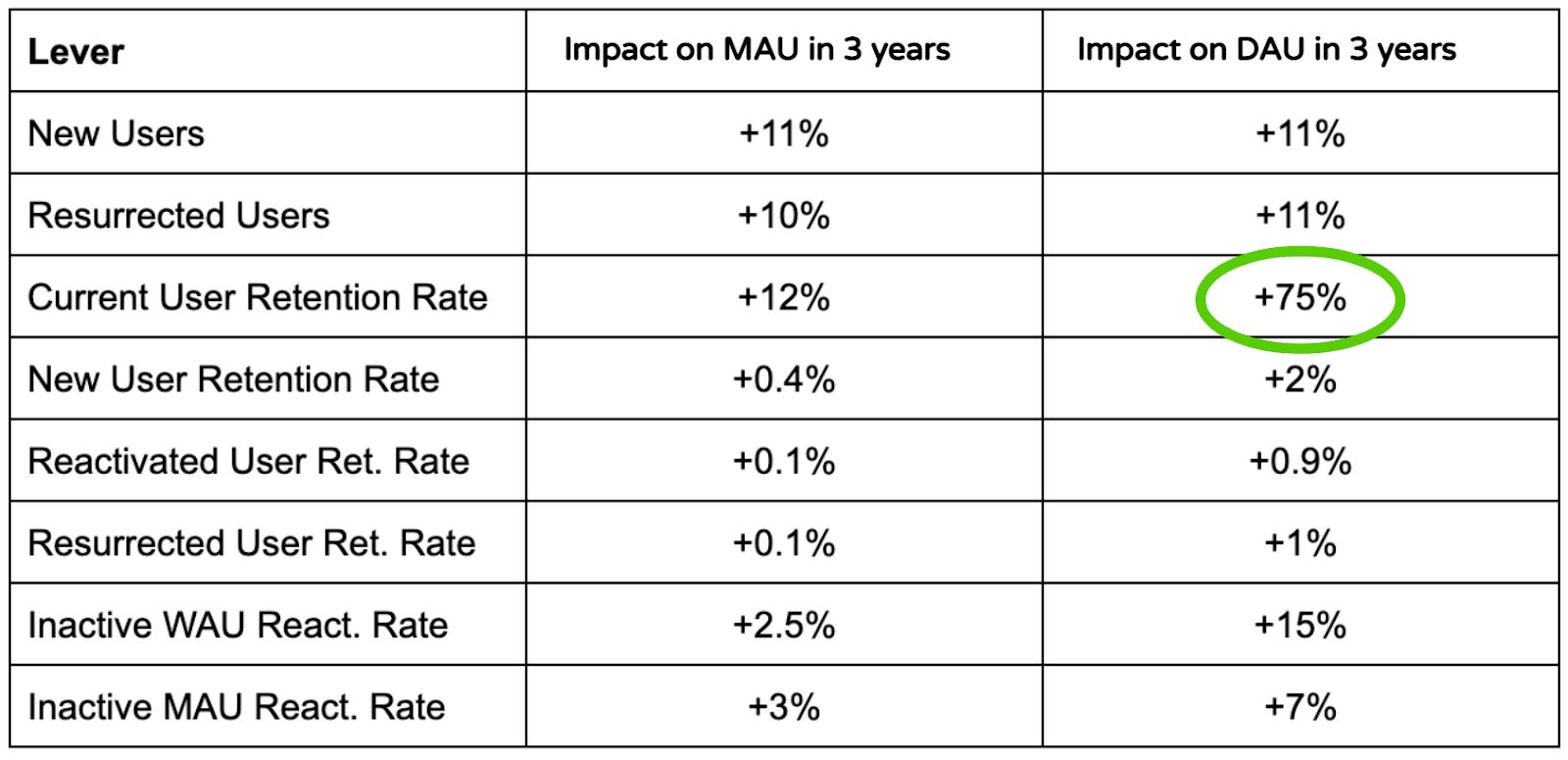
저희는 CURR 이 DAU 에 거대한 영향을 미친다는 것을 즉각 확인할 수 있었고, 이는 두 번째로 효과가 좋은 지표보다도 5배나 큰 값이었습니다. 돌이켜보면 CURR 의 발견은 이치에도 맞았고, 활발하게 이용하는 현재 사용자가 동일한 세그먼트로 유지된다는 꽤나 흥미로운 특성도 가지고 있었습니다.
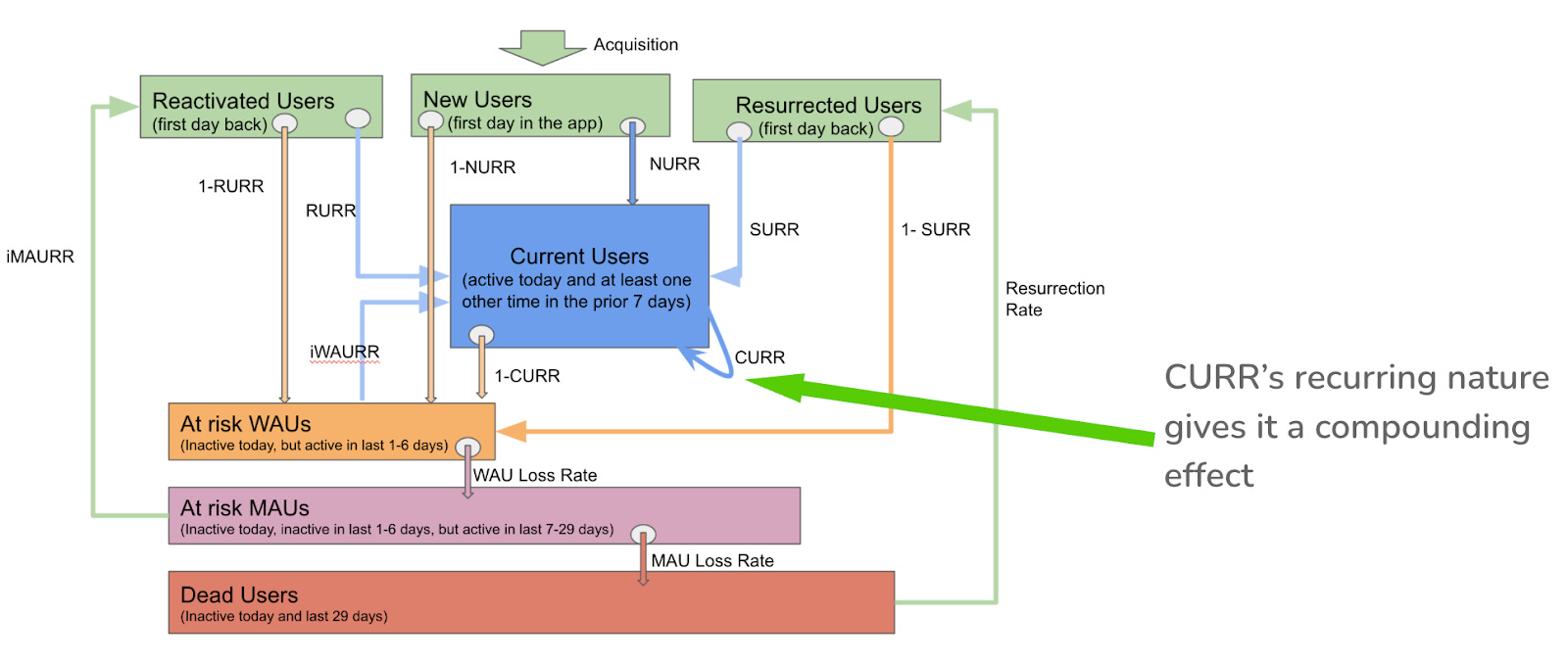
이 특성은 복리 효과를 의미하는 것이었으며, CURR 이 움직이기 어려운 지표이지만, 움직일 수만 있다면 훨씬 더 큰 효과를 낼 수 있다는 말이기도 했습니다. 이러한 분석에 기반하여, 저희가 원하는 전략적인 돌파구를 얻기위해서는 CURR 을 움직여야 한다는 것을 깨달았습니다. 그래서 CURR 을 북극성 지표로 하는 새로운 팀인 리텐션팀 (Retention Team) 을 만들기로 결정하였습니다.
CURR 에 집중하는 것의 가장 큰 장점 중 하나는 신규 사용자 리텐션 (new-user retention) 과 같은 이전에 중요하다고 생각했던 것들에 대해 신경을 쓰지 않기로 결정한 것이었습니다. 이는 신규 사용자에게 우선적으로 수많은 그로스 실험을 진행하여 오랜 기간 큰 성장을 이끌어낸 회사로써는 매우 큰 마인드셋의 변화였습니다.
하나 더 크게 깨달은 게 있다면, 한 지표가 DAU 와 MAU 에 끼치는 영향력에도 크게 차이가 있을 수 있다는 것이었습니다. CURR 이 DAU 에 끼치는 영향은 MAU 의 6배였습니다. iWAURR (비활성 WAU 재활성률; inactive WAU reactivation rate) 은 DAU 에 두 번째로 크게 영향을 끼치는 지표였지만, MAU 에 있어서는 신규와 부활 사용자 유지율에 이어서 4등이었습니다. 이 말인 즉슨, 어느 시점에는 MAU 를 크게 성장시키기 위해서 신규 사용자 획득을 성장시킬 수 있는 새로운 벡터를 찾아야 한다는 것이었죠. 하지만 당분간 저희는 DAU 를 움직이는 데에 집중하려고 했고, 다른 성장 레버들 보다 CURR 에 우선순위를 뒀습니다. 그리고 이 선택이 옳았다는 것을 증명했습니다.
실험을 한 번 진행했는데 통계적으로 유의하지 못한 결과를 얻었습니다. 기간을 조금 더 두고 실험을 하자니 시간이 오래 걸릴 것 같은데 기존 결과를 그대로 포함해서 실험 기간을 늘려서 보면 안 되나요?
A/B 테스트란 무엇이고, 제가 왜 이게 통계학을 망치고 있다고 생각하는지 설명드리고자 합니다.
이 글은 AI가 데이터베이스에 직접 접근해 인간 전문가처럼 데이터를 분석하는 새로운 워크플로우를 소개합니다. 단순한 질의응답을 뛰어넘는 이러한 도약은 데이터 분석가의 역할이 근본적으로 재정의될 미래를 암시합니다.
이 글은 넷플릭스 (Netflix) 에서의 분석 엔지니어링 (Analytics Engineering) 관련 업무의 범위를 공유하기 위한 여러 편의 글 중 두 번째 글이며, 최근에 열렸던 분석 엔지니어링 컨퍼런스에서 발표된 내용이기도 합니다. 더 많은 내용이 궁금하신가요? 첫 번째 ...
듀오링고의 350% 성장의 뒷 이야기, 리더보드, 연속 학습, 알림, 그리고 혁신적인 그로스 모델 들어가기에 앞서
듀오링고의 350% 성장의 뒷 이야기, 리더보드, 연속 학습, 알림, 그리고 혁신적인 그로스 모델 들어가기에 앞서
듀오링고의 350% 성장의 뒷 이야기, 리더보드, 연속 학습, 알림, 그리고 혁신적인 그로스 모델
원문: Meaningful metrics: How data sharpened the focus of product teams
원문: Sequential Testing at Booking.com
가장 좋은 방법은 당연히 영어 밖에 사용하지 못하는 환경에 강제로 처해지는 것이겠지만 그것이 어려우니…
고민의 흔적을 보여주세요
을 찾습니다.
원문: Charts & Accessibility
모수, 큰 수의 법칙, 그리고 중심극한정리에 대하여
그리고 여러분들도 (아마도) 하지 않아야 하는 이유
회사 서비스의 추천 시스템을 개선하기 위해 팀 내에서 (아직까진 두 명이긴 하지만) 지난 두 달 동안 스터디를 진행했습니다. 얼마 전 두 번째 스터디가 끝났고 이에 대한 회고를 해보려고 합니다.
원문: Dark Side of Data: Privacy by Emre Rencberoglu
원문: RStudio Projects and Working Directories: A Beginner’s Guide by Martin Chan
원문: TidyTuesday GitHub Repository
원문: How programming languages got their names
원문: How to Make Meetings Less Terrible 팟캐스트: How to Make Meetings Less Terrible (Ep. 389)
생키 다이어그램 (Sankey Diagram) 은 흐름(Flow) 다이어그램의 한 종류로써 그 화살표의 너비로 흐름의 양을 비율적으로 보여준다.
2년 전 일본어로 책을 내긴 했지만 대부분의 독자들이 이 책을 읽을 수는 없을 것 같았다.
자기회귀 모형이란 무엇인가?
회귀분석을 실행하기 위해 필요한 가정과 조건들에 대해 알아보자.
통계적 검정과 회귀분석에서 자주 사용되는 정규성 가정과 정규성 검정에 대해 알아보자.
여러 통계 검정과 모형에서 사용되는 독립성 가정에 대해 알아보자.
시계열 모형 중 ARMA 모형에대해 알아보자.
시각화에서 주의할 점인 넓이를 표시하는 원칙에 대해 알아보자.
평균 양쪽의 z-값들 사이의 넓이를 구하는 방법에 대해 알아보자.
분산분석의 개념과 방법에 대해 알아보자.
분산분석(ANOVA; ANalysis Of VAriance) 와 회귀분석의 개념을 섞은 공분산분석(ANCOVA; ANalysis of COVAriance)에 대해 알아보자. 이 글을 이해하기 위해서는 아래의 글을 먼저 읽는 것이 좋다.
Akaike’s Information Criterion 의 정의와 이를 구하는 방법에 대해 알아보자.
수정된 R제곱과 그 용도에 대해서 알아보자.
통계 용어 중 정확도(Accuracy)와 정밀도(Precision) 에 대해서 알아보자.
절대 오차와 평균 절대 오차에 대해서 알아보자.
가설 검정이란 무엇이며, 가설 검정의 다양한 방법에 대해 알아보자.
회귀분석이란 무엇이며, 회귀분석 과정에서 사용하는 용어와 다양한 방법에 대해 알아보자.
이 글은 MathJax 를 GitHub Pages Jekyll blog 에 추가하는 방법을 다룬다. 이탤릭체로 된 부분은 본문에는 없고 제가 따라하면서 고치거나 추가한 부분이니 참고하세요.
모집단과 표본집단을 이용하는 경우 통계학에서 말하는 10% 조건이 무엇인지에 대해 알아보자.
여러분의 GitHub 블로그에 Jupyter notebook 을 바꿔서 올릴 수 있도록 도와줄 글입니다. 직접 바꾸는 방법은 1회성 글들을 위해서 추가했고, 변환 과정과 파일 이동, 그리고 여러분의 블로그에 올리는 것까지 한 번에 할 수 있는 자동화 bash 를 만드는 자세한 방법...
68 95 99.7의 법칙이란 무엇인가?
단위근 검정 방법 중 하나인 Augmented Dickey Fuller 검정에 대해 알아보자.
이 자료는 데이터 과학과 관련된 특정 주제에 대한 연재물이며, 다룰 주제는 다음과 같다. 회귀분석, 군집화, 신경망, 딥러닝, 의사결정나무, 앙상블, 상관관계, 파이썬, R, 텐서플로우, SVM, 데이터 축소, 피쳐 선택, 실험 계획법, 교차검증, 모델 피팅 등. 이 글을 계속 받...